
Some were more solid than others.. The biggest one IMHO is when we go to 100 core, 100MMUs dont make sese.Sorry, but I found some of these to be...less than solid, if you excuse me.
Yes some archs do it better the above is a software driven HW TLB."TLB flushes on context switch" : That depends on how the CPU implements paging, and how much it tries to manage the TLB itself. On an arch without hardware assisted TLB loading, the kernel can, especially for a special purpose kernel, which has say, only one task, easily partition the TLB and manage entries on it own. So it splits up the TLB half and half and doesn't flush TLB entries on context switch. Simply because x86 walks the page tables automatically and therefore has to flush on each context switch doesn't mean that 'flushing on context switch' is an attribute of CPUs with TLBs.
It also depends on the OS , some OS avoid changing user address spaces just for this reason.
Yes this isnt an either or , but IMHO more if nto all should be done in software."TLB miss on Page Table Lookup" : Even in software, a cache would be of a fixed size, otherwise it would be useless. If the cache is allowed to grow indefinitely then lookup time increases. So it would be expected that a TLB could only have N entries. Again, simply because x86 walks the tables on its own, and decides to leave the programmer out of the whole deal, doesn't mean the the idea of a PMMU is bad: on an arch which does not have hardware assisted TLB loading, one can easily, in one's TLB management code, when 'flushing' an entry from a TLB, store it in a fast cache of flushed entries in RAM. The idea would be that "These entries were at one time in the TLB, and will likely be accessed again. So storing in them in some fast data structure in software would speed up TLB loads in software."
You can have Sparc like software managed TLB
An OS patching addresses in software ,
Position independent code
or even the software emulating a Virtual address system ( using pathching and relocation to achieve the goal) .
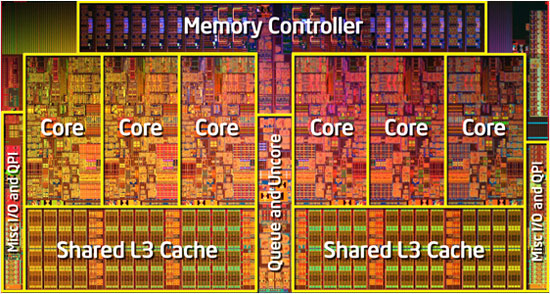
While x86s are the worst due to their huge core size the have one of the smallest MMUs
Only the most highly tuned code can be tuned for caches and its time consuming and expensive besides the old -Os. ( having just tuned a CAS producer /Consumer queue) most code will never use this. The industry is moving towards higher level languages witness python , PHP , Ruby and Java script these also need to run fast and will cross page boundaries frequently ( and with little consideration) ."TLB miss requires expensive page table walk ... proliferate cache cooling" : True. But when software is written with caches in mind, the programmer tends to have the process image as condensed as is possible. Also, the need for a TLB lookup is only really existent when a new page is accessed. That means that a 4K boundary of instructions or data fetches must be crossed before a new TLB load may need to be initiated. 4K is a lot of bytes of instructions, and a modest bit of data, too. You may say: "Jumps will easily invalidate that argument", but I would say: "A data/instruction cache line is usually of a pretty small size, so really, the number of potential cache misses is high whether or not you have to walk page tables."
The hash is too slow ( remember like cache you really want this to complete in < a few cycles) so it uses a mechanism like cache ( but faster ) and like cache it makes the chips more powerhungry. Again ( i know im repeating) 100 MMU like 100 Caches dont make sense . We may have a L1 small TLB and L2 slower and shared TLB in such a scenario meaning page misses will be even more expensive."The TLB lookup is a power hungry parrallel search ( on all entries in the list since a linear search or hash would be too slow) for each lookup.
Nothing that cant be done in software more efficiently." : I can't speak with much authority on this one, but generally a hash works well for any kind of cache that has a tuple field which can be sensibly split on some modulo value. Virtual addresses in a TLB can be hashed, and associativity can be used to, again, speed up the lookups.
All these things are taken care off and it works , GCs makes it easy ( and compact) , stopping the threads and moving a app to remove fragmentation is quicker than a disk write. An OS can also detect an idle process and put it to sleep and page out the whole or part of a process - witness how fast an entire machine can hibernate compared to how it just dies when you have 2 * the memory load and swapping. A big sequentail write and read being much better than a large amount of Random access pages.I'm not sure where your research paper came from, but maybe those people need to redo their research and come up with some better reasons for not using PMMUs. Also, they haven't considered the great alleviation that is the removal of the problem of address space fragmentation. Without paging, you have one fixed address space within which to load all processes. When a process is killed, it leaves a hole in this fixed linear address space. As you create and kill more processes, you'll end up having processes scattered everywhere, and eventually, due to placement problems, you'll need to move one or more processes around to find room for other new ones (but how do you do that quickly?), or else just tell the user: "Close one of more programs, and we'll play lotto to see whether that will free enough contiguous space to load a new process."
In terms of running out of memory the other option we suffer from today is death by swapping from a bug in an allocation routine or over comitment , my machine has suffered from this a few times .. anyway swapping is a different discussion.
And all of the above is predicated on solving the concurrency problem and high core counts which requires some changes to the way we write apps.--Nice read altogether,
Personally i think there will be a big break with the past in 5-10 years . And the following all require changing the way we write apps
- Capability security ( no ambient authority and little global data)
- Asyncronous runtime ( to improve concurrency & work better in a network connectected world)
- Immutable data eg Ocml ( to improve concurrency )
- Software memory protection ( no untrusted code , though compiled type safe and memory safe code is fine) .
So im bundling it in one , but note im cheating i still allow a few C user apps / libs to ease the migration process. The above will create an OS that is far faster on multicore as well as being far more reliable ( including self healing and sub application failure allowing the app to heal and continue) and secure though it will be "strange".





{kind=link}