
in Linux 0.01, the nmi are set up as traps... but from what I was told in this forum, it's supposed to
be set up as interrupts...
setting it up as traps means not need to do sti and cli... potentially meaning nmi handler could get interrupted... because traps do not, by default, disable interrupts...
do you see the inconsistency here? if I declare in IDT, NMI handler as traps.. will processor still disable the intertupts?
earliest linux 0.01 inconsistency with James Molloy's tutori

Re: earliest linux 0.01 inconsistency with James Molloy's tu
The NMI has a higher priority than any other interrupt.

Re: earliest linux 0.01 inconsistency with James Molloy's tu
The manual seems to contradict itself on this point.
The processor also invokes certain hardware conditions to insure that no other interrupts, including NMI interrupts, are received until the NMI handler has completed executing
It is recommended that the NMI interrupt handler be accessed through an interrupt gate to disable maskable hardware interrupts
Re: earliest linux 0.01 inconsistency with James Molloy's tu
Is it perhaps saying that, although the interrupts won't be delivered during NMI processing, it may be desirable to discard them rather than holding them pending?
-
Octocontrabass
- Member

- Posts: 5885
- Joined: Mon Mar 25, 2013 7:01 pm
Re: earliest linux 0.01 inconsistency with James Molloy's tu
NMI prevents all further external interrupts until the next IRET instruction.
Disabling maskable interrupts is a good idea because the next IRET instruction may not be the end of your NMI handler. For example, if your NMI handler causes an exception, your exception handler might return using IRET and re-enable interrupts that way.
Either way, maskable interrupts are not discarded.
Disabling maskable interrupts is a good idea because the next IRET instruction may not be the end of your NMI handler. For example, if your NMI handler causes an exception, your exception handler might return using IRET and re-enable interrupts that way.
Either way, maskable interrupts are not discarded.
Re: earliest linux 0.01 inconsistency with James Molloy's tu
Thank you all for the posting! I have done some detailed research on Bochs....
my conclusion is that if you declare NMI handler as traps, it is a *bug*... NMI handler will not
disable the IF for you... so 0.01 version of linux is full of bugs!!!
my conclusion is that if you declare NMI handler as traps, it is a *bug*... NMI handler will not
disable the IF for you... so 0.01 version of linux is full of bugs!!!

Re: earliest linux 0.01 inconsistency with James Molloy's tu
As signified by the version number...
Every good solution is obvious once you've found it.
-
Octocontrabass
- Member
- Posts: 5885
- Joined: Mon Mar 25, 2013 7:01 pm
Re: earliest linux 0.01 inconsistency with James Molloy's tu
The CPU has a hidden internal flag to block interrupts when NMI is signaled. It's a good idea to also use an interrupt gate to clear IF, but it's not required.ITchimp wrote:if you declare NMI handler as traps, it is a *bug*... NMI handler will not
disable the IF for you...
Re: earliest linux 0.01 inconsistency with James Molloy's tu
I have tried on bochs, to set NMI as traps and IF is not cleared when calling the NMI handler...
also NMI can trigger other NMI. so NMI can be nested ... this is a article to read but to be clear
https://lwn.net/Articles/484932/
also NMI can trigger other NMI. so NMI can be nested ... this is a article to read but to be clear
https://lwn.net/Articles/484932/
Re: earliest linux 0.01 inconsistency with James Molloy's tu
I am still reading the article, I thank the author for sharing this very insightful article with us. but I still find his explanation somewhat hard to understand
The x86 NMI iret flaw
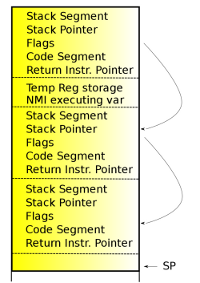
[Stack layout] First NMI on x86_64
On x86, like other architectures, the CPU will not execute another NMI until the first NMI is complete. The problem with the x86 architecture, with respect to NMIs, is that an NMI is considered complete when an iret instruction is executed. iret is the x86 instruction that is used to return from an interrupt or exception. When an interrupt or exception triggers, the hardware will automatically load information onto the stack that will allow the handler to return back to what it interrupted in the state that it was interrupted. The iret instruction will use the information on the stack to reset the state.
The flaw on x86 is that an NMI will be considered complete if an exception is taken during the NMI handler, because the exception will return with an iret. If the NMI handler triggers either a page fault or breakpoint, the iret used to return from those exceptions will re-enable NMIs. The NMI handler will not be put back to the state that it was at when the exception triggered, but instead will be put back to a state that will allow new NMIs to preempt the running NMI handler. If another NMI comes in, it will jump into code that is not designed for re-entrancy. Even worse, on x86_64, when an NMI triggers, the stack pointer is set to a fixed address (per CPU). If another NMI comes in before the first NMI handler is complete, the new NMI will write all over the preempted NMIs stack. The result is a very nasty crash on return to the original NMI handler. The NMI handler for i386 uses the current kernel stack, like normal interrupts do, and does not have this specific problem.
A common example where this can be seen is to add a stack dump of a task into an NMI handler. To debug lockups, a kernel developer may put in a show_state() (shows the state of all tasks like the sysrq-t does) into the NMI watchdog handler. When the watchdog detects that the system is locked up, the show_state() triggers, showing the stack trace of all tasks. The reading of the stack of all tasks is carefully done because a stack frame may point to a bad memory area, which will trigger a page fault.
The kernel expects that a fault may happen here and handles it appropriately. But the page fault handler still executes an iret instruction. This will re-enable NMIs. The print-out of all the tasks may take some time, especially if it is going out over the serial port. This makes it highly possible for another NMI to trigger before the output is complete, causing the system to crash. The poor developer will be left with a partial dump and not have a backtrace of all the tasks. There is a good chance that the task that caused the problem will not be displayed, and the developer will have to come up with another means to debug the problem.
Because of this x86 NMI iret flaw, NMI handlers must neither trigger a page fault nor hit a breakpoint. It may sound like page faults should not be an issue, but this restriction prevents NMI handlers from using memory allocated by vmalloc(). The vmalloc() code in the kernel maps virtual memory in the kernel address space. The problem is that the memory is mapped into a task's page table when it is first used. If an NMI handler uses the memory, and that happens to be the first time the current task (the one executing when the NMI took place) referenced the memory, it will trigger a page fault.
[Stack layout] Nested NMI on x86_64A vmalloc() page fault does not need to take locks as all it does is fill in the task's page table, thus there should be no problem with using vmalloc() memory in an NMI handler. But because the iret from the page fault will enable NMIs again, vmalloc() memory must be avoided in NMIs to prevent the above race. Kernel modules are loaded using vmalloc(), and the text sections of a loaded module are in virtual memory that are page faulted in on use. If a module were to register an NMI handler callback, that callback could cause the NMI to become re-entrant.
As breakpoints also return with an iret, they must not be placed in NMI handlers either. This prevents kprobes from being placed in NMI handlers. Kprobes are used by ftrace, perf, and several other tracing tools to insert dynamic tracepoints into the kernel. But if a kprobe is added to a function called by a NMI handler, it may become re-entrant due to the iret called by the breakpoint handler.
The x86 NMI iret flaw
[Stack layout] First NMI on x86_64
On x86, like other architectures, the CPU will not execute another NMI until the first NMI is complete. The problem with the x86 architecture, with respect to NMIs, is that an NMI is considered complete when an iret instruction is executed. iret is the x86 instruction that is used to return from an interrupt or exception. When an interrupt or exception triggers, the hardware will automatically load information onto the stack that will allow the handler to return back to what it interrupted in the state that it was interrupted. The iret instruction will use the information on the stack to reset the state.
The flaw on x86 is that an NMI will be considered complete if an exception is taken during the NMI handler, because the exception will return with an iret. If the NMI handler triggers either a page fault or breakpoint, the iret used to return from those exceptions will re-enable NMIs. The NMI handler will not be put back to the state that it was at when the exception triggered, but instead will be put back to a state that will allow new NMIs to preempt the running NMI handler. If another NMI comes in, it will jump into code that is not designed for re-entrancy. Even worse, on x86_64, when an NMI triggers, the stack pointer is set to a fixed address (per CPU). If another NMI comes in before the first NMI handler is complete, the new NMI will write all over the preempted NMIs stack. The result is a very nasty crash on return to the original NMI handler. The NMI handler for i386 uses the current kernel stack, like normal interrupts do, and does not have this specific problem.
A common example where this can be seen is to add a stack dump of a task into an NMI handler. To debug lockups, a kernel developer may put in a show_state() (shows the state of all tasks like the sysrq-t does) into the NMI watchdog handler. When the watchdog detects that the system is locked up, the show_state() triggers, showing the stack trace of all tasks. The reading of the stack of all tasks is carefully done because a stack frame may point to a bad memory area, which will trigger a page fault.
The kernel expects that a fault may happen here and handles it appropriately. But the page fault handler still executes an iret instruction. This will re-enable NMIs. The print-out of all the tasks may take some time, especially if it is going out over the serial port. This makes it highly possible for another NMI to trigger before the output is complete, causing the system to crash. The poor developer will be left with a partial dump and not have a backtrace of all the tasks. There is a good chance that the task that caused the problem will not be displayed, and the developer will have to come up with another means to debug the problem.
Because of this x86 NMI iret flaw, NMI handlers must neither trigger a page fault nor hit a breakpoint. It may sound like page faults should not be an issue, but this restriction prevents NMI handlers from using memory allocated by vmalloc(). The vmalloc() code in the kernel maps virtual memory in the kernel address space. The problem is that the memory is mapped into a task's page table when it is first used. If an NMI handler uses the memory, and that happens to be the first time the current task (the one executing when the NMI took place) referenced the memory, it will trigger a page fault.
[Stack layout] Nested NMI on x86_64A vmalloc() page fault does not need to take locks as all it does is fill in the task's page table, thus there should be no problem with using vmalloc() memory in an NMI handler. But because the iret from the page fault will enable NMIs again, vmalloc() memory must be avoided in NMIs to prevent the above race. Kernel modules are loaded using vmalloc(), and the text sections of a loaded module are in virtual memory that are page faulted in on use. If a module were to register an NMI handler callback, that callback could cause the NMI to become re-entrant.
As breakpoints also return with an iret, they must not be placed in NMI handlers either. This prevents kprobes from being placed in NMI handlers. Kprobes are used by ftrace, perf, and several other tracing tools to insert dynamic tracepoints into the kernel. But if a kprobe is added to a function called by a NMI handler, it may become re-entrant due to the iret called by the breakpoint handler.
Re: earliest linux 0.01 inconsistency with James Molloy's tu
I think NMIs should only happen when something is very wrong and their handlers should be minimal: e.g. log an event (if at all possible, given the restrictions) and reset or shut down the system. Recovery may not be a viable option.